Исследование эффектов обработки естественного языка на анализ медицинских документов.

Современная медицина сегодня обрабатывает огромные объемы информации, генерируемой в результате проведения обследований пациентов. Однако, большинство данных хранится в неструктурированной форме, что затрудняет их анализ и использование для принятия важных решений. В связи с этим, все большую популярность набирает область исследований, связанных с обработкой естественного языка и его применением в медицинских задачах.
Обработка естественного языка (Natural Language Processing, NLP) – это наука, которая занимается разработкой методов и алгоритмов для обработки и анализа текстов на естественных языках. Ее целью является создание компьютерных систем, способных понимать и работать с естественным языком, таким образом облегчая взаимодействие между компьютером и человеком.
Одной из важных областей применения NLP является анализ медицинских документов. Автоматическая обработка и анализ медицинских текстов позволяет извлекать ценные знания и информацию из таких документов, как медицинские записи, отчеты об обследованиях, результаты лабораторных исследований, истории болезни и т.д. Эти данные могут быть использованы для мониторинга состояния пациента, разработки новых лекарств, определения эффективности терапии, идентификации побочных эффектов и многих других медицинских задач.
Предварительное исследование
Перед тем как приступить к анализу медицинских документов, проведено предварительное исследование для оценки последствий обработки естественного языка. Главная цель этого исследования состояла в выявлении преимуществ и ограничений данного подхода.
Методика исследования
Для проведения исследования была собрана выборка медицинских документов различной структуры и сложности. Документы были представлены в виде текстовых файлов и содержали информацию о заболеваниях, симптомах, лечении, истории болезни и других важных аспектах. Выборка включала как электронные медицинские записи, так и отсканированные страницы из бумажных документов.
Для обработки и анализа документов был использован алгоритм обработки естественного языка, основанный на методе машинного обучения. Перед применением алгоритма, документы были предварительно обработаны, включая удаление лишних символов, тегов и форматирования. Затем алгоритм проводил анализ каждого документа и извлекал важные медицинские характеристики и сущности.
Результаты исследования
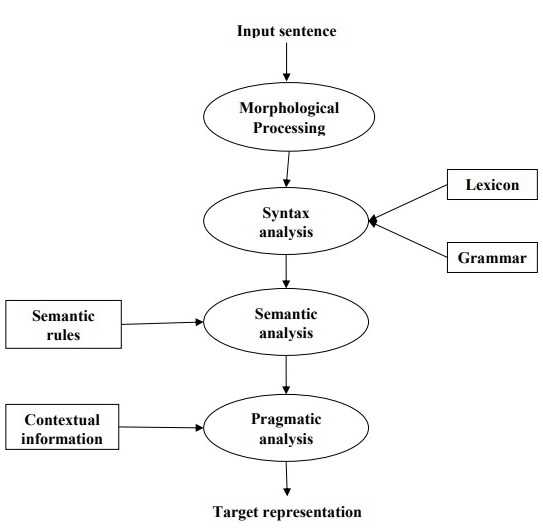
Результаты предварительного исследования показали, что обработка естественного языка может быть эффективным инструментом для анализа медицинских документов. Алгоритм корректно распознавал и извлекал важную информацию из различных типов документов. Более того, обработка естественного языка позволила автоматизировать процесс анализа и значительно снизить время, затрачиваемое на его выполнение.
Однако, было также обнаружено несколько ограничений данного подхода. Некоторые особенности форматирования и структуры документов могли влиять на точность распознавания и извлечения информации. Кроме того, в случае отсутствия стандартизации форматов документов, могла возникать необходимость в настройке алгоритма под конкретный тип документа или медицинскую систему.
Заключение
Предварительное исследование показало, что обработка естественного языка имеет потенциал для значительного улучшения анализа медицинских документов. Однако перед применением данного подхода необходимо учитывать его ограничения и особенности конкретного контекста использования.
Влияние обработки естественного языка
Обработка естественного языка (Natural Language Processing, NLP) играет важную роль в анализе медицинских документов. Эта технология позволяет компьютерам «понимать» и обрабатывать естественный язык, что открывает множество новых возможностей для извлечения информации из текстовой формы.
Первое влияние обработки естественного языка в анализе медицинских документов заключается в возможности автоматического извлечения сущностей, таких как названия болезней, лекарственных препаратов, лечебных процедур и т.д. Это позволяет быстро и точно анализировать огромные объемы текстовой информации. Такие данные могут быть полезны для исследований и анализа трендов в медицине.
Второе влияние обработки естественного языка заключается в автоматическом классификации текстов. Такие алгоритмы могут быстро определить, является ли текст медицинской записью, рецензией пациента или научной статьей. Это помогает структурировать и организовывать информацию для более удобного доступа и поиска.
Третье влияние обработки естественного языка заключается в возможности анализировать пациентские записи и выявлять в них паттерны и связи. Например, с помощью NLP можно автоматически выявить нежелательные эффекты лекарственных препаратов, определить факторы риска для развития заболеваний или проанализировать эффективность определенного лечения на основе данных о пациентах.
В целом, обработка естественного языка играет важную роль в анализе медицинских документов, позволяя автоматизировать и улучшить процессы исследования, анализа и организации текстовой информации. Эта технология имеет большой потенциал для улучшения пациентского ухода и развития медицинской науки.
Последствия для анализа медицинских документов

Основными последствиями применения NLP для анализа медицинских документов являются:
1. Улучшение эффективности и точности анализа
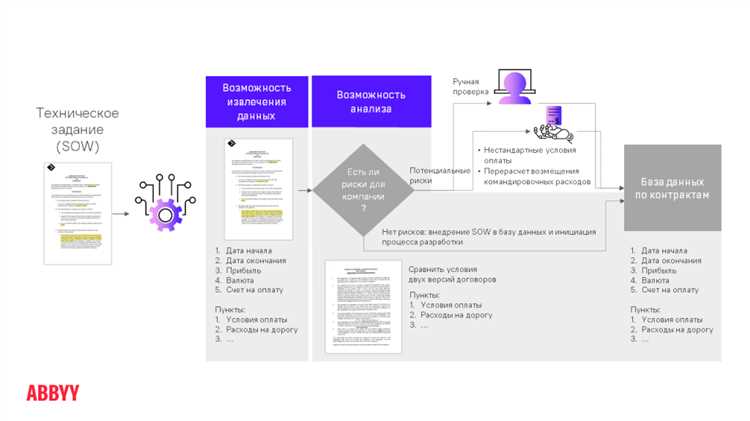
NLP позволяет автоматизировать процесс анализа медицинских документов и уменьшить время, затраченное на оценку информации. Автоматическое распознавание и извлечение ключевых фактов, симптомов, диагнозов и лечения позволяет быстрее и точнее определить состояние пациента и разработать план лечения.
2. Улучшение предсказательных моделей и исследований
Использование NLP для анализа медицинских документов позволяет обнаруживать скрытые взаимосвязи и паттерны, которые могут быть использованы для разработки предсказательных моделей и проведения медицинских исследований. Это позволяет выявить новые факторы риска, изучить эффективность терапий и улучшить предсказательную способность моделей.
Важно отметить, что применение NLP для анализа медицинских документов имеет свои ограничения и вызывает определенные проблемы. Некорректное распознавание синонимов, семантических связей или отсутствие контекста может привести к неверному интерпретации информации. Поэтому, проведение ручной проверки и подтверждение результатов, полученных с помощью NLP, является важной частью процесса анализа медицинских документов.
Увеличение точности результатов
Обработка естественного языка стала неотъемлемой частью анализа медицинских документов и постепенно заменяет ручной труд, что увеличивает эффективность и точность получаемых результатов. Однако, для достижения наивысшей точности следует обратить внимание на несколько важных аспектов:
Качественные алгоритмы обработки
Выбор подходящего алгоритма для обработки медицинской информации является неотъемлемой частью увеличения точности результатов. Алгоритмы должны быть способными улавливать ключевые фразы, определять связи между понятиями и правильно классифицировать тексты. Постоянное совершенствование и оптимизация алгоритмов позволяет достичь наилучших результатов.
Корректная предобработка текста

Одним из важных шагов в обработке медицинских документов является предобработка текста. Корректная лемматизация, стемминг, удаление стоп-слов и специфичных терминов помогает улучшить качество анализа и исключить ненужную информацию.
Например: при анализе исследований пациентов с диагнозом «сахарный диабет» можно исключить слово «сахарный», чтобы фокусироваться только на понятии «диабет».
Использование специализированных словарей
В области медицины используются специализированные словари, содержащие термины, синонимы, аббревиатуры, а также определения и связи между ними. Использование таких словарей позволяет точнее классифицировать тексты и уменьшить количество ложных срабатываний.
Например: при использовании словаря медицинских терминов, анализатор может точно определить, что слово «тромбоз» относится к категории «заболевания сосудов», а не к категории «кровь».
Перспективы обработки естественного языка
Одной из главных проблем, с которыми сталкиваются специалисты в области медицинской информатики, является огромный объем медицинских текстов, которые необходимо проанализировать. Ручная обработка и анализ такого количества данных занимает огромное количество времени и труда. В этой ситуации обработка естественного языка может стать незаменимым инструментом, позволяющим автоматизировать процесс анализа и извлечения информации из медицинских документов.
NLP предоставляет возможность автоматического извлечения ключевой информации из медицинской документации, такой как диагноз, лечение и прогнозы. Это делает процесс обработки медицинской информации более эффективным, позволяет сократить количество ошибок и повысить качество анализа.
Кроме того, обработка естественного языка может помочь в проведении масштабных исследований, анализе эффективности лекарственных препаратов и выявлении побочных эффектов, определении пациентов с определенными признаками риска или определенными заболеваниями.
Также NLP может быть использовано для улучшения взаимодействия между пациентами и медицинскими системами. Автоматический анализ текстовых данных может помочь в создании интеллектуальных средств для ввода и извлечения информации, что упростит процесс взаимодействия пациентов с медицинскими системами и повысит их эффективность.
Перспективы обработки естественного языка в медицине огромны. Эта область исследования может помочь в совершенствовании медицинской практики, повышении эффективности анализа медицинских данных и улучшении взаимодействия между пациентами и системами здравоохранения.
Вопрос-ответ:
Какая роль играет обработка естественного языка в анализе медицинских документов?
Обработка естественного языка (NLP) играет важную роль в анализе медицинских документов, таких как истории болезни, результаты лабораторных исследований, эпикризы и т.д. С помощью NLP можно автоматически извлекать информацию из текстов и преобразовывать ее в числовой или структурированный формат, что позволяет улучшить эффективность работы медицинского персонала, повысить качество диагностики и лечения пациентов.
Какие могут быть последствия обработки естественного языка для анализа медицинских документов?
Последствия обработки естественного языка для анализа медицинских документов могут быть разнообразными. Одно из последствий — автоматизация процесса анализа большого объема текстов и ускорение работы медицинского персонала. Это позволяет быстрее и точнее выявлять патологии, определять риски развития заболеваний и выбирать наиболее эффективные методы лечения. Однако, существуют также потенциальные риски, связанные с точностью и надежностью использования NLP в анализе медицинских текстов, такие как ошибки в извлечении информации или неправильное толкование результатов.
Какие методы обработки естественного языка применяются в анализе медицинских документов?
В анализе медицинских документов применяются различные методы обработки естественного языка. Например, методы машинного обучения, такие как классификация и кластеризация текстов, позволяют автоматически обнаруживать и категоризировать информацию в текстах. Технологии NER (Named Entity Recognition) используются для извлечения именованных сущностей, таких как имена пациентов, названия болезней, лекарств и т.д. Синтаксический и семантический анализ текстов помогает понять структуру предложений и связи между словами, что может быть полезно при определении смысла текста и выявлении взаимосвязей между различными понятиями.
Какие проблемы решает обработка естественного языка в медицинских документах?
Обработка естественного языка позволяет автоматизировать анализ медицинских документов, что способствует улучшению качества и оперативности медицинского обслуживания. С ее помощью можно извлекать информацию о симптомах, диагнозах, лечении и прогнозе заболеваний, а также осуществлять мониторинг и анализ медицинских данных.